What is derivatives?
- A derivative of a function at any point tells us how much a minute increment to the argument of the function will increment the value of the function
To be clear, what we want is not differentiable, but how the change effects the outputs.
- Based on the fact that at a fine enough resolution, any smooth, continuous function is locally linear at any point. So we can express like this
Multivariate scalar function
The partial derivative gives us how increments when only is incremented
It can be expressed as:
where
Optimization
Single variable
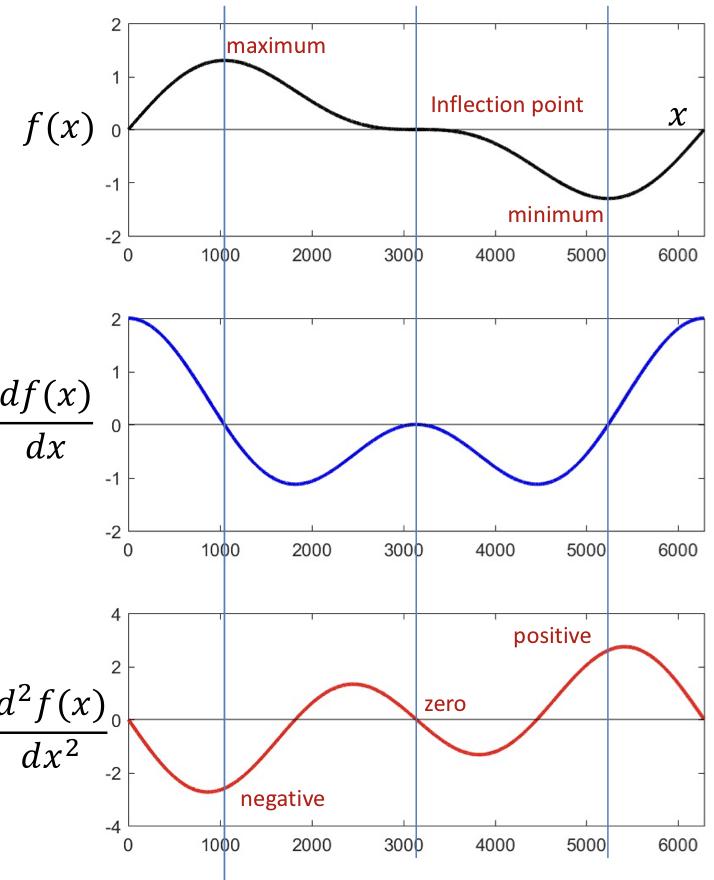
- Three different critical point with zero derivative
- The second derivative is
- at minima
- at maxima
- at inflection points
multiple variables
- The gradient is the transpose of the derivative (give us the change in for tiny variations in )
- This is a vector inner product
- is max if is aligned with
The gradient is the direction of fastest increase in
Hessian
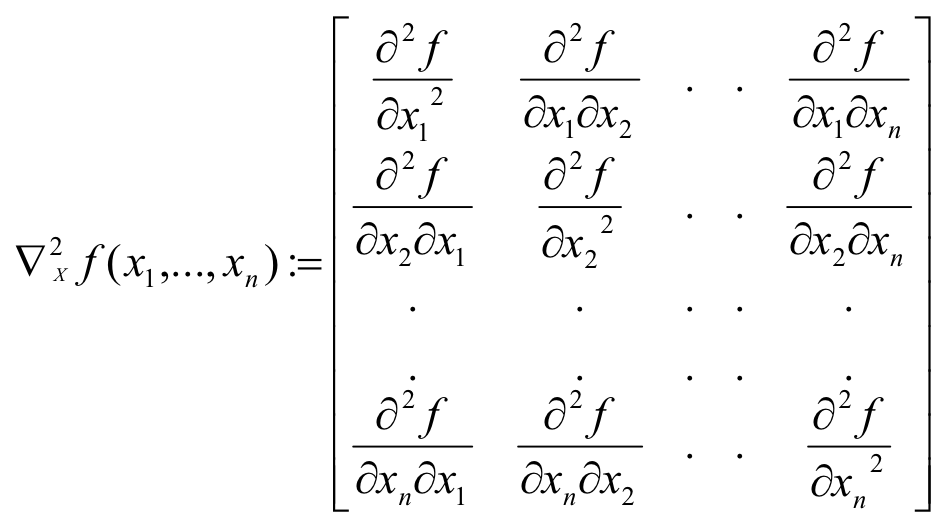
Unconstrained Minimization of function
- Solve for where the derivative equals to zero:
- Compute the Hessian Matrix at the candidate solution and verify that
- Hessian is positive definite (eigenvalues positive) -> to identify local minima
- Hessian is negative definite (eigenvalues negative) -> to identify local maxima
Closed form are not available
- To find a maximum move in the direction of the gradient
- To find a minimum move exactly opposite the direction of the gradient
- Choose steps
- fixed step size
- iteration-dependent step size: critical for fast optimization
Convergence
- For convex functions
- gradient descent will always find the minimum.
- For non-convex functions
- it will find a local minimum or an inflection point