建表
create table t1 (c1 int primary key, c2 int );
create table t2 (c1 int primary key, c2 int );
-- 插入测试数据
insert into t1 SELECT generate_series(1,10000) as key, (random()*(10^3))::integer;
insert into t2 SELECT generate_series(1,10000) as key, (random()*(10^3))::integer;
查看查询计划:
explain select * from t1,t2 where t1.c1<5 and t1.c2 = t2.c2;
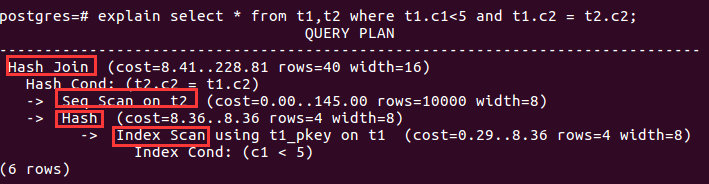
可以发现,在这个SQL语句的查询树中,lefttree对应的是SeqScan,righttree对应的是Hash,即左树(outer relation)为t2的顺序扫描运算生成的relation,右树(inner relation)为t1的索引扫描(Index Scan)运算生成的relation(在此relation上创建Hash Table)
源码解读
ExecHashJoinImpl函数把Hash Join划分为多个阶段/状态(有限状态机),保存在HashJoinState->hj_JoinState字段中,这些状态分别是分别为:
- HJ_BUILD_HASHTABLE:创建Hash表;
- HJ_NEED_NEW_OUTER:扫描outer relation,计算外表连接键的hash值,把相匹配元组放在合适的bucket中;
- HJ_SCAN_BUCKET:扫描bucket,匹配的tuple返回
- HJ_FILL_OUTER_TUPLE:当前outer relation元组已耗尽,因此检查是否发出一个虚拟的外连接元组。
- HJ_FILL_INNER_TUPLES:已完成一个批处理,但做的是右外连接/完全连接,填充虚拟连接元组
- HJ_NEED_NEW_BATCH:开启下一批次
注意:在work_mem不足以装下Hash Table时,分批执行.每个批次执行时,会把outer relation与inner relation匹配(指hash值一样)的tuple会存储起来,放在合适的批次文件中(hashtable->outerBatchFile[batchno]),以避免多次的outer relation扫描
对于之前提到的SQL语句,有如下执行步骤
- 首先对t1表进行Index scan,建立Hash表(对应状态
HJ_BUILD_HASHTABLE) - 对每个Outer的Tuple,计算Hash值,放到合适的Bucket中(对应状态
HJ_NEED_NEW_OUTER) - 扫描Bucket,匹配Tuple(对应状态
HJ_SCAN_BUCKET) - 如果当前Tuple已经没有匹配了,转到状态
HJ_FILL_OUTER_TUPLE
火山模型一定要返回一个tuple,如果hash值没有,则找下一个,因此每次计算hash值的次数不确定。
当成功放回一个tuple后,当前位置的指针也需要保留,因为不清楚是否对于当前key的join是否完全匹配。
GDB
首先对HashJoin打断点:
b ExecHashJoin
然后每次next,查看node->hj_JoinState的变化过程