工作原理
系统流程
当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
Clinent
- Client 为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程(Streaming的任务),也可以不结束并等待结果返回。
任务
- 将用户程序翻译成逻辑执行计划(类似sparkDAG)
- 逻辑执行计划的优化
JobManager
- JobManager 主要负责调度 Job 并协调 Task 做 checkpoint,职责上很像 Storm 的 Nimbus。从 Client 处接收到 Job 和 JAR 包等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
任务
- 管理TaskManager
- 调度
- 协调
TaskManager
- TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,Task 为线程。从 JobManager 处接收需要部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
任务
- 与JobManager、TaskManager保持通信
- 启动Task线程,实际执行任务
- 相同节点或不同节点上Task线程进行数据交换
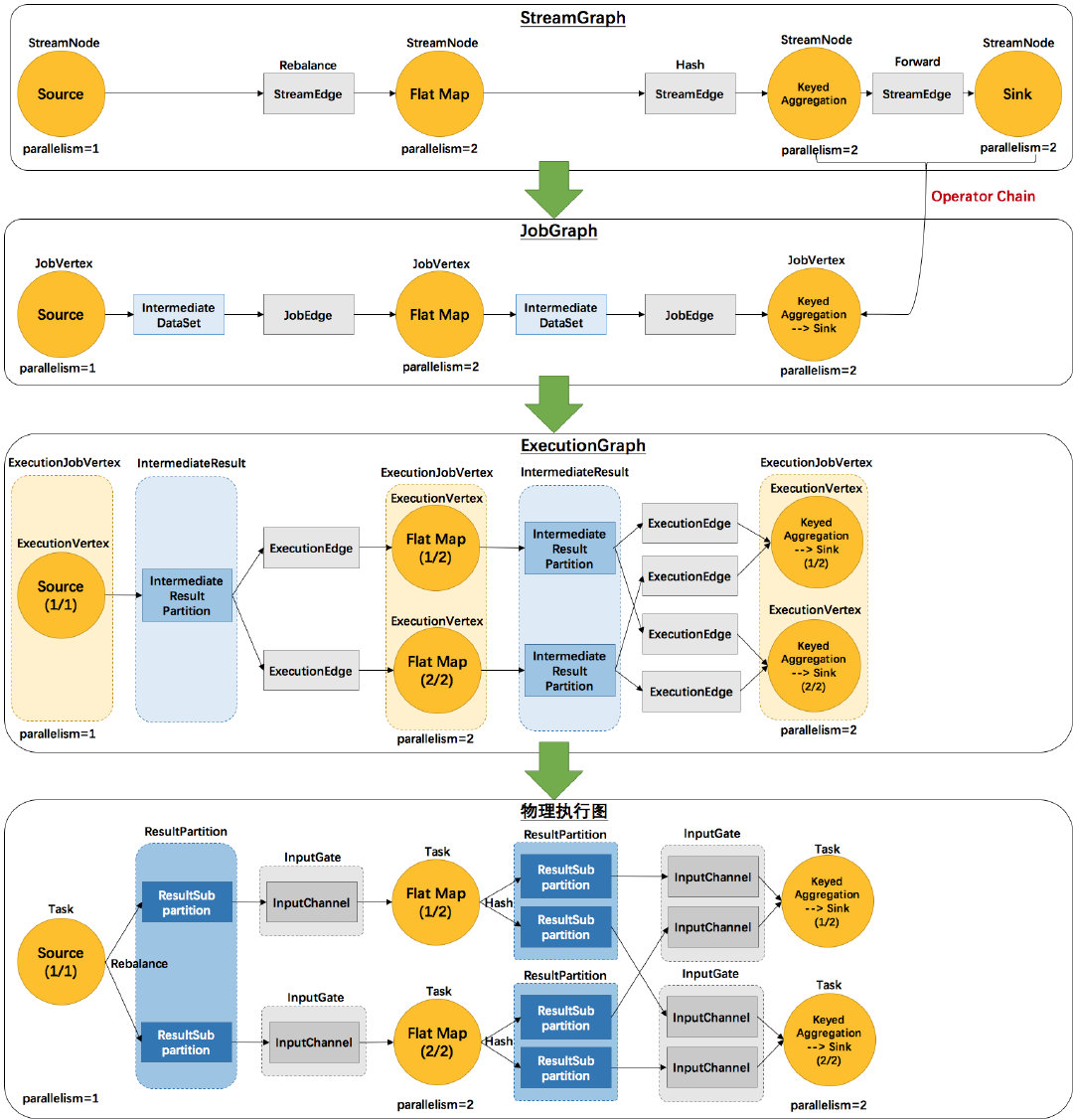
Graph
批处理:Program → BatchGraph → Optimized BatchGraph → JobGraph
流计算:Program → StreamGraph → JobGraph
- StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
- ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
| 涵义 | 流计算 | 批处理 | 部件 |
|---|---|---|---|
| 用户程序 | Stream API程序 | Batch API程序 | Client |
| 程序的拓扑结构 | StreamGraph | DAG/Optimizer | Client |
| 逻辑执行计划 | JobGraph | JobGraph | Client |
| 物理执行计划 | ExecutionGraph | ExecutionGraph | JobManager |
| 物理实现 | 分布式执行 | 分布式执行 | TaskManager |
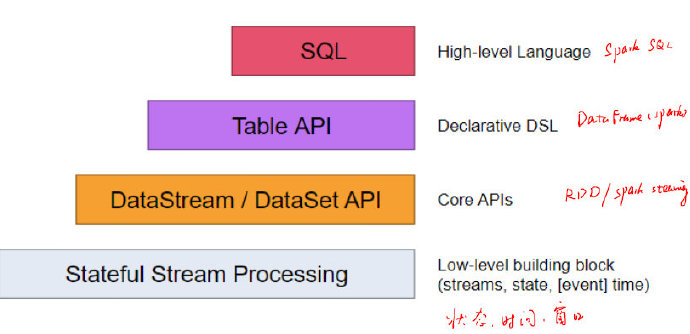
Flink API
与Spark对比
Process Function

理论上实现了以上三个函数,就可以定义任意算子
DatatStream/DataSet
DataStream API

DataStream Iteration
在Flink中,不显式定义循环,而是通过iterationBody实现循环操作

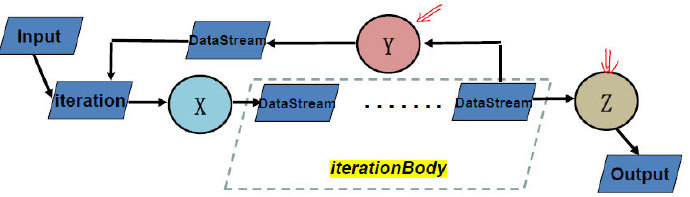
这里的iterationBody接收X的输入,并根据最后的closeWith完成一次迭代,另外的数据操作Z退出迭代。
DataSet API
定义的算子与DataStream类似,主要还是考虑迭代过程。
DataSet Bulk Iteration

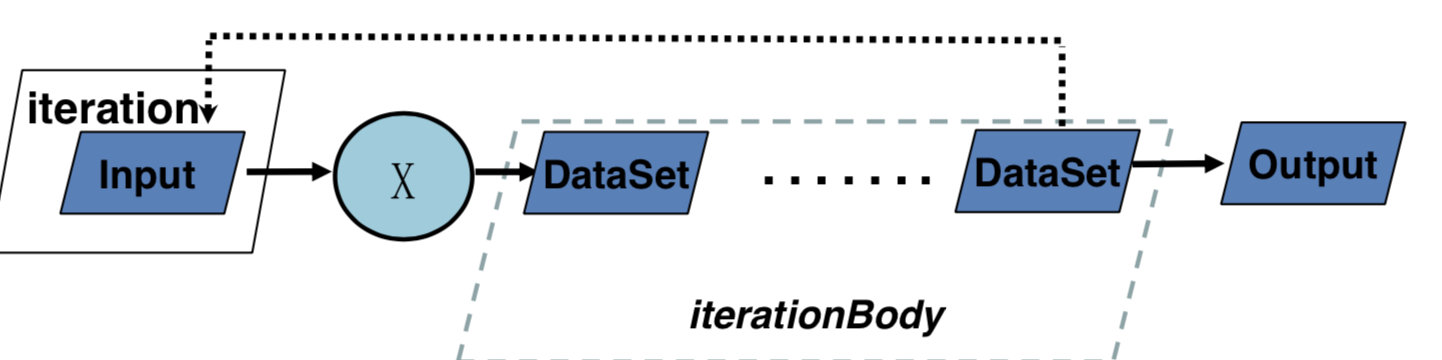
可以发现与DataStream类似,但必须要迭代结束才能有输出。
同时,除了设置最大迭代次数,在closeWith中还可以添加第二个DataSet,当其为空时,则退出循环。
与流计算的区别:
- Input会有源源不断的来,且迭代过程中会有数据进入
- Output随时都可以输出
DataSet Delta Iteration
由于在图计算中有很多算法在每次迭代中,不是所有TrainData都参与运算,所以定义Delta算子。
workset是每次迭代都需要进行更新的,而solution set不一定更新。

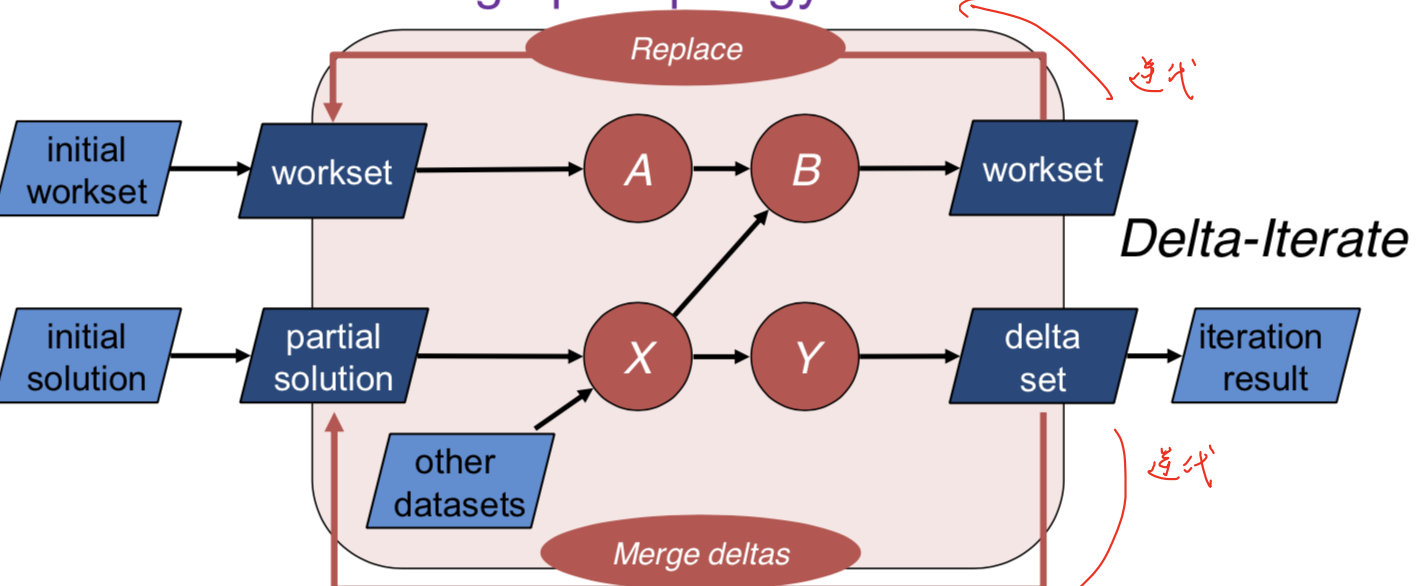
可以通过iteration.getWorkset/getSolutionSet得到对应的DataSet,同时分别进行计算,当nextWorkset为空时,退出循环。
在迭代过程中,nextWorkSet是直接替代当前的workset,而deltaSet是merge到solutionSet。
key positions是什么?
指定生成的值的键是哪一个属性。
Table&SQL
Table API 与SQL基本相同,只是在SQL中,由于是字符串语句,在编译时无法查错。
批流等价转换
主要是想要让SQL在Steam上运行。

为了实现这种功能,Flink设计了Dynamic Table对Stream进行相互转换。
Stream → Dynamic Table
- Append mode
- 很简单,直接添加一项即可
- Upsert mode
- 需要将相同key的值更新或者插入
- 同样支持SQL和Window操作
Dynamic Table → Stream
为了容错,使用Undo/Redo日志
容错机制
使用checkpoint的方式
非迭代过程的容错
对于批处理和流计算是一样的
Pipelined Snapshots
- Asynchronous approache
- Light checkpoint
- Distributed snapshots
- Exactly-once guarantee
迭代过程的容错
流式迭代
属于有环的Pipelined Snapshots
将迭代的数据看作虚拟的输入
批式迭代
特点:循环不结束,没有输出
两种CheckPointing方法:
- Tail checkpoint
- Head checkpoint