+++ title = "Storm 编程练习" slug = "storm coding" tags = ["distributed system","project"] date = "2018-11-28T19:51:51+08:00" description = ""
+++
WordSort
要求
将之前的WordCount改为WordSort排序
思路
同样,使用一个list来记录当前位置,同时使用二分查找找到当前位置并插入
代码实现
SentenceSpout
public class SentenceSpout extends BaseRichSpout {
private SpoutOutputCollector spoutOutputCollector;
private String[] sentences = {"the cow jumped over the moon", "an apple a day keeps the doctor away",
"four score and seven years ago", "snow white and the seven dwarfs", "i am at two with nature"};
public void open(Map map, TopologyContext topologycontext, SpoutOutputCollector spoutoutputcollector) {
this.spoutOutputCollector = spoutoutputcollector;
}
public void nextTuple() {
for (String sentence : sentences) {
Values values = new Values(sentence);
UUID msgId = UUID.randomUUID();
this.spoutOutputCollector.emit(values, msgId);
}
Utils.sleep(1000);
}
public void declareOutputFields(OutputFieldsDeclarer outputfieldsdeclarer) {
outputfieldsdeclarer.declare(new Fields("sentence"));
}
}
SplitSentenceBolt
public class SplitSentenceBolt extends BaseBasicBolt {
public void execute(Tuple tuple, BasicOutputCollector collector) {
String sentence = tuple.getStringByField("sentence");
String[] words = sentence.split(" ");
for (String word : words) {
collector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer outputfieldsdeclarer) {
outputfieldsdeclarer.declare(new Fields("word"));
}
}
WordSortBolt
public class WordSortBolt extends BaseBasicBolt {
List<String> wordList = new ArrayList<String>();
/**
* @param array
* @param key
* @return
*/
public int arrayIndexOf(String key) {
int min, max, mid;
min = 0;
max = wordList.size() - 1;
while (min <= max) {
mid = (min + max) >> 1;
String tmp = wordList.get(mid);
if (key.compareTo(tmp) > 0) {
min = mid + 1;
} else if (key.compareTo(tmp) < 0) {
max = mid - 1;
} else {
return mid;
}
}
return min;
}
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getString(0);
if (wordList == null) {
wordList.add(word);
System.out.println(word);
} else {
int addIndex = arrayIndexOf(word);
wordList.add(addIndex,word);
for (String tmp:wordList
) {
System.out.println(tmp);
}
}
collector.emit(new Values(word));
}
public void declareOutputFields(OutputFieldsDeclarer outputfieldsdeclarer) {
outputfieldsdeclarer.declare(new Fields("word"));
}
}
WordSortTopology
public class WordSortTopology {
public static void main(String[] args) throws Exception {
SentenceSpout sentenceSpout = new SentenceSpout();
SplitSentenceBolt splitSentenceBolt = new SplitSentenceBolt();
WordSortBolt wordSortBolt = new WordSortBolt();
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("sentenceSpout-1", sentenceSpout);
builder.setBolt("splitSentenceBolt-1", splitSentenceBolt).shuffleGrouping("sentenceSpout-1");
builder.setBolt("wordSortBolt-1", wordSortBolt).fieldsGrouping("splitSentenceBolt-1", new Fields("word"));
Config config = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("wordSortTopology-1", config, builder.createTopology());
Thread.sleep(999999999);
cluster.shutdown();
}
}
运行
将程序打包成JAR包,并执行
storm jar WordSort.jar WordSortTopology ws
查看结果,不断有新的tuple进来并排序打印:
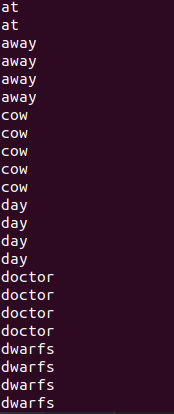
top-k
要求
单词的top-k:求最频繁的k个word
要考虑代码的性能
思路
- 首先仍然与WordCount一样,需要一个hashmap来存当前word对应的count数量
- 考虑到性能原因,肯定不能直接对所有word进行排序,因此,只需要维护前k个word即可
- 需要设置最小count,表示前k个中最小的count数,如果当前有word的count数大于这个数,则将其加入TopK数组,然后剔除最小count的word
代码实现
SentenceSpout、SplitSentenceBolt与之前一样,不再赘述
pair
保存word和count的tuple,方便访问
public class pair {
public final String content;
public final Integer count;
public pair(String content, Integer count) {
this.content = content;
this.count = count;
}
public int compareCount(pair other) {
return this.count - other.count;
}
public int compareWord(pair other) {
return this.content.compareTo(other.content);
}
}
TopK
使用HashMap来保存当前所有word的count数量,使用TopList保存前k个word
public class TopK extends BaseBasicBolt {
private HashMap<String, Integer> counts;
private ArrayList<pair> TopList;
public int K;
public int minCount;
TopK(int k) {
this.K = k;
this.counts = new HashMap<>();
this.TopList = new ArrayList<>();
this.minCount = 0;
}
public void insertWord(pair word) {
int max = TopList.size() - 1;
// if the same word, the new.count > old.count
for (int i = max; i >= 0; i--) {
pair tmp = TopList.get(i);
// find the same word,replace older one
if (word.compareWord(tmp) == 0) {
TopList.set(i, word);
return;
}
if (word.compareCount(tmp) <= 0) {
TopList.add(i + 1, word);
return;
}
}
TopList.add(0, word);
}
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getStringByField("word");
Integer count = counts.get(word);
if (count == null) {
count = 0;
}
count++;
this.counts.put(word, count);
if (count > minCount || TopList.size() < K) {
insertWord(new pair(word, count));
if (TopList.size() > K) {
TopList.remove(TopList.size() - 1);
minCount = TopList.get(TopList.size() - 1).count;
}
for (pair tmpWord : TopList)
System.out.println(tmpWord.content + " " + tmpWord.count.toString());
collector.emit(new Values(word, count));
}
}
public void declareOutputFields(OutputFieldsDeclarer outputfieldsdeclarer) {
outputfieldsdeclarer.declare(new Fields("word", "count"));
}
}
WordTopKTopology
public class WordTopKTopology {
public static void main(String[] args) throws Exception {
SentenceSpout sentenceSpout = new SentenceSpout();
SplitSentenceBolt splitSentenceBolt = new SplitSentenceBolt();
TopK wordTopKBolt = new TopK(5);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("sentenceSpout-1", sentenceSpout);
builder.setBolt("splitSentenceBolt-1", splitSentenceBolt).shuffleGrouping("sentenceSpout-1");
builder.setBolt("wordTopKBolt-1", wordTopKBolt).shuffleGrouping("splitSentenceBolt-1");
Config config = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("wordTopKTopology-1", config, builder.createTopology());
Thread.sleep(999999999);
cluster.shutdown();
}
}
运行
将代码打包成JAR包,并执行:
storm jar TopK.jar WordTopKTopology tk
结果为:
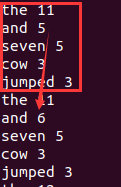
可以发现,始终能输出前k个词频最高的词。