PageRank
数据准备
边:
1 2
1 15
2 3
2 4
2 5
2 6
2 7
3 13
4 2
5 11
5 12
6 1
6 7
6 8
7 1
7 8
8 1
8 9
8 10
9 14
9 1
10 1
10 13
11 12
11 1
12 1
13 14
14 12
15 1
网页:
1 2
2 5
3 1
4 1
5 2
6 3
7 2
8 3
9 2
10 2
11 2
12 1
13 1
14 1
15 1
将这两个文件放入HDFS:
hdfs dfs -mkdir input/PageRank
hdfs dfs -put links.txt input/PageRank
hdfs dfs -put pagesHadoop.txt input/PageRank
编写程序
PageRank
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URISyntaxException;
import static java.lang.StrictMath.abs;
public class PageRank {
private static final String CACHED_PATH = "output/cache";
private static final String ACTUAL_PATH = "output/Graph/HadoopPageRank";
public static final int maxIterations = 500;
public static final double threshold = 0.0001;
public static final double dumping = 0.85;
public static int pageNum = 0;
public static void main(String[] args) throws IOException,
InterruptedException, ClassNotFoundException, URISyntaxException {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if (otherArgs.length != 3) {
System.err.println("Usage: PageRank <PagePath> <LinksPath> <PageNum>");
System.exit(2);
}
int code = 0;
Path PagePath = new Path(otherArgs[0]);
Path LinksPath = new Path(otherArgs[1]);
pageNum = Integer.parseInt(otherArgs[2]);
conf.set("pageNum", pageNum + "");
conf.set("dumping", dumping + "");
Path cachePath = new Path(CACHED_PATH);
Path actualPath = new Path(ACTUAL_PATH);
// Delete output if exists
FileSystem hdfs = FileSystem.get(conf);
if (hdfs.exists(actualPath))
hdfs.delete(actualPath, true); // recursive delete
// prepare original rank
for (int i = 1; i <= pageNum; i++)
writeFileByline(ACTUAL_PATH + "/part-r-00000", i + " " + 1.0 / pageNum);
int counter = 0;
boolean changed = true;
while (counter < maxIterations && changed) {
// Delete output if exists
if (hdfs.exists(cachePath))
hdfs.delete(cachePath, true);
//moving the previous iteration file to the cache directory
hdfs.rename(actualPath, cachePath);
conf.set("mapreduce.output.textoutputformat.separator", " ");
conf.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator", " ");
Job PageRank = Job.getInstance(conf, "PageRank " + (counter + ""));
// add cache
PageRank.addCacheFile(PagePath.toUri());
PageRank.setJarByClass(PageRankMapper.class);
FileInputFormat.addInputPath(PageRank, LinksPath);
// set out put path : output/means
FileOutputFormat.setOutputPath(PageRank, actualPath);
PageRank.setMapperClass(PageRankMapper.class);
PageRank.setInputFormatClass(KeyValueTextInputFormat.class);
PageRank.setMapOutputKeyClass(IntWritable.class);
PageRank.setMapOutputValueClass(DoubleWritable.class);
PageRank.setReducerClass(PageRankReducer.class);
PageRank.setOutputKeyClass(IntWritable.class);
PageRank.setOutputValueClass(DoubleWritable.class);
// Execute job
code = PageRank.waitForCompletion(true) ? 0 : 1;
//checking if the mean is stable
BufferedReader file1Reader = new BufferedReader(new InputStreamReader(hdfs.open(new Path(CACHED_PATH + "/part-r-00000"))));
BufferedReader file2Reader = new BufferedReader(new InputStreamReader(hdfs.open(new Path(ACTUAL_PATH + "/part-r-00000"))));
for (int i = 0; i < pageNum; i++) {
double rank1 = Double.parseDouble(file1Reader.readLine().split(" ")[1]);
double rank2 = Double.parseDouble(file2Reader.readLine().split(" ")[1]);
if (abs(rank1 - rank2) <= threshold) {
changed = false;
} else {
changed = true;
break;
}
}
file1Reader.close();
file2Reader.close();
counter++;
System.out.println("PageRank finished iteration:>> " + counter + " || rank change: " + changed);
}
System.exit(code);
}
public static void writeFileByline(String dst, String contents) throws IOException {
Configuration conf = new Configuration();
Path dstPath = new Path(dst);
FileSystem fs = dstPath.getFileSystem(conf);
FSDataOutputStream outputStream = null;
if (!fs.exists(dstPath)) {
outputStream = fs.create(dstPath);
} else {
outputStream = fs.append(dstPath);
}
contents = contents + "\n";
outputStream.write(contents.getBytes("utf-8"));
outputStream.close();
}
}
PageRankMapper
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.*;
public class PageRankMapper extends Mapper<Text, Text, IntWritable, DoubleWritable> {
Map<Integer, Double> rank = new HashMap<>();
Map<Integer, Integer> pages = new HashMap<>();
/**
* reading the rank from the distributed cache
*/
public void setup(Context context) throws IOException, InterruptedException {
String lineString = null;
// read rank file
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
FSDataInputStream hdfsInStream = fs.open(new Path("output/cache/part-r-00000"));
InputStreamReader isr = new InputStreamReader(hdfsInStream, "utf-8");
BufferedReader br = new BufferedReader(isr);
while ((lineString = br.readLine()) != null) {
String[] keyValue = StringUtils.split(lineString, " ");
rank.put(Integer.parseInt(keyValue[0]), Double.parseDouble(keyValue[1]));
}
br.close();
// read pages file
String PagesFiles = context.getLocalCacheFiles()[0].getName();
br = new BufferedReader(new FileReader(PagesFiles));
while ((lineString = br.readLine()) != null) {
String[] keyValue = StringUtils.split(lineString, " ");
pages.put(Integer.parseInt(keyValue[0]), Integer.parseInt(keyValue[1]));
}
br.close();
}
public void map(Text from, Text to, Context context) throws IOException, InterruptedException {
int fromPoint = Integer.parseInt(from.toString());
int toPoint = Integer.parseInt(to.toString());
double newRank = rank.get(fromPoint) * (1.0 / pages.get(fromPoint));
context.write(new IntWritable(toPoint), new DoubleWritable(newRank));
}
}
PageRankReducer
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class PageRankReducer extends Reducer<IntWritable, DoubleWritable, IntWritable, DoubleWritable> {
public void reduce(IntWritable key, Iterable<DoubleWritable> values, Context context) throws IOException,
InterruptedException {
Configuration conf = context.getConfiguration();
int pageNum = Integer.parseInt(conf.get("pageNum"));
double dumping = Double.parseDouble(conf.get("dumping"));
double rank = 0.0;
for (DoubleWritable value : values)
rank += value.get();
rank = (1 - dumping) * (1.0/pageNum) + dumping * rank;
context.write(key, new DoubleWritable(rank));
}
}
思路:
- 首先指定
KeyValueTextInputFormat,并指定page个数(在Hadoop中不太好直接求) - 将每个顶点的出度文件
pagesHadoop作为distributionCache,并首先将初始rank值写入cache文件中 - 每次读cache文件中的rank值,再进行计算,写入目标文件中,前后的rank值进行比较,若不满足阈值,将更新后的rank值写入cache中继续进行迭代
运行
hadoop jar PageRank.jar input/PageRank/pagesHadoop.txt input/PageRank/links.txt 15
可以发现,Hadoop执行循环操作,比spark、flink慢很多
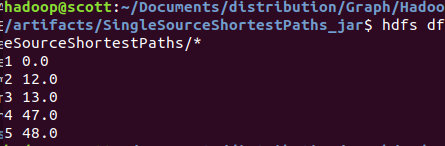
查看结果:

hdfs dfs -cat output/Graph/HadoopPageRank/*
ConnectedComponents
数据准备
提供基本数据集,与PageRank一样,指定顶点和边
vertices.txt
准备一些顶点,例如1-16
edges.txt
准备一些连接边:
1 2
2 3
2 4
3 5
6 7
8 9
8 10
5 11
11 12
10 13
9 14
13 14
1 15
16 1
放入HDFS:
hdfs dfs -mkdir input/ConnectedComponents
hdfs dfs -put edges.txt input/ConnectedComponents
编写程序
ConnectedComponents
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URISyntaxException;
public class ConnectedComponents {
private static final String CACHED_PATH = "output/cache";
private static final String ACTUAL_PATH = "output/Graph/HadoopConnectedComponents";
public static final int maxIterations = 100;
public static int verticesNum = 0;
public static void main(String[] args) throws IOException,
InterruptedException, ClassNotFoundException, URISyntaxException {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: PageRank <EdgesPath> <verticesNum>");
System.exit(2);
}
int code = 0;
Path EdgesPath = new Path(otherArgs[0]);
verticesNum = Integer.parseInt(otherArgs[1]);
conf.set("verticesNum", verticesNum + "");
Path cachePath = new Path(CACHED_PATH);
Path actualPath = new Path(ACTUAL_PATH);
// Delete output if exists
FileSystem hdfs = FileSystem.get(conf);
if (hdfs.exists(actualPath))
hdfs.delete(actualPath, true); // recursive delete
// prepare original ConnectedComponents
for (int i = 1; i <= verticesNum; i++)
writeFileByline(ACTUAL_PATH + "/part-r-00000", i + " " + i);
int counter = 0;
boolean changed = true;
while (counter < maxIterations && changed) {
// Delete output if exists
if (hdfs.exists(cachePath))
hdfs.delete(cachePath, true);
//moving the previous iteration file to the cache directory
hdfs.rename(actualPath, cachePath);
conf.set("mapreduce.output.textoutputformat.separator", " ");
conf.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator", " ");
Job PageRank = Job.getInstance(conf, "ConnectedComponents " + (counter + ""));
PageRank.setJarByClass(ConnectedComponents.class);
FileInputFormat.addInputPath(PageRank, EdgesPath);
FileOutputFormat.setOutputPath(PageRank, actualPath);
PageRank.setMapperClass(ConnectedComponentsMapper.class);
PageRank.setInputFormatClass(KeyValueTextInputFormat.class);
PageRank.setMapOutputKeyClass(IntWritable.class);
PageRank.setMapOutputValueClass(IntWritable.class);
PageRank.setReducerClass(ConnectedComponentsReduer.class);
PageRank.setOutputKeyClass(IntWritable.class);
PageRank.setOutputValueClass(IntWritable.class);
// Execute job
code = PageRank.waitForCompletion(true) ? 0 : 1;
//checking if the mean is stable
BufferedReader file1Reader = new BufferedReader(new InputStreamReader(hdfs.open(new Path(CACHED_PATH + "/part-r-00000"))));
BufferedReader file2Reader = new BufferedReader(new InputStreamReader(hdfs.open(new Path(ACTUAL_PATH + "/part-r-00000"))));
for (int i = 0; i < verticesNum; i++) {
double component1 = Double.parseDouble(file1Reader.readLine().split(" ")[1]);
double component2 = Double.parseDouble(file2Reader.readLine().split(" ")[1]);
if (component1 == component2) {
changed = false;
} else {
changed = true;
break;
}
}
file1Reader.close();
file2Reader.close();
counter++;
System.out.println("ConnectedComponents finished iteration:>> " + counter + " || component change: " + changed);
}
System.exit(code);
}
public static void writeFileByline(String dst, String contents) throws IOException {
Configuration conf = new Configuration();
Path dstPath = new Path(dst);
FileSystem fs = dstPath.getFileSystem(conf);
FSDataOutputStream outputStream = null;
if (!fs.exists(dstPath)) {
outputStream = fs.create(dstPath);
} else {
outputStream = fs.append(dstPath);
}
contents = contents + "\n";
outputStream.write(contents.getBytes("utf-8"));
outputStream.close();
}
}
ConnectedComponentsMapper
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.*;
public class ConnectedComponentsMapper extends Mapper<Text, Text, IntWritable, IntWritable> {
Map<Integer, Integer> components = new HashMap<>();
/**
* reading the rank from the distributed cache
*/
public void setup(Context context) throws IOException, InterruptedException {
String lineString = null;
// read rank file
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
FSDataInputStream hdfsInStream = fs.open(new Path("output/cache/part-r-00000"));
InputStreamReader isr = new InputStreamReader(hdfsInStream, "utf-8");
BufferedReader br = new BufferedReader(isr);
while ((lineString = br.readLine()) != null) {
String[] keyValue = StringUtils.split(lineString, " ");
components.put(Integer.parseInt(keyValue[0]), Integer.parseInt(keyValue[1]));
}
br.close();
}
public void map(Text from, Text to, Context context) throws IOException, InterruptedException {
int fromPoint = Integer.parseInt(from.toString());
int toPoint = Integer.parseInt(to.toString());
context.write(new IntWritable(toPoint), new IntWritable(components.get(fromPoint)));
context.write(new IntWritable(fromPoint), new IntWritable(components.get(fromPoint)));
}
}
ConnectedComponentsReduer
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ConnectedComponentsReduer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> {
public void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException,
InterruptedException {
Configuration conf = context.getConfiguration();
int component = Integer.parseInt(conf.get("verticesNum"));
for (IntWritable value : values) {
if (value.get() < component)
component = value.get();
}
context.write(key, new IntWritable(component));
}
}
思路:
- 与PageRank一样,需要准备cache文件作为初始化连通分量,每次得到新的结果与cache文件进行比较,如果有更新则继续迭代
- 在map中,为了保证每个点都会出现在reduce中,将
from点和to点都输入到reduce中
运行
hadoop jar ConnectedComponents.jar input/ConnectedComponents/edges.txt 16
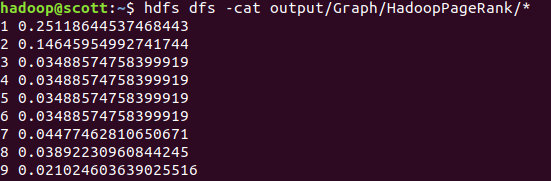
迭代了6次:

hdfs dfs -cat output/Graph/HadoopConnectedComponents/*
最后结果为:
SingleSourceShortestPaths
数据准备
首先我们需要准备边和点
边:
1 2 12.0
1 3 13.0
2 3 23.0
3 4 34.0
3 5 35.0
4 5 45.0
5 1 51.0
放入HDFS:
hdfs dfs -mkdir input/SingleSourceShortestPaths
hdfs dfs -put edges.txt input/SingleSourceShortestPaths
编写程序
SingleSourceShortestPaths
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URISyntaxException;
import static java.lang.StrictMath.abs;
public class SingleSourceShortestPaths {
private static final String CACHED_PATH = "output/cache";
private static final String ACTUAL_PATH = "output/Graph/HadoopSingleSourceShortestPaths";
public static final int maxIterations = 100;
private static final double EPSILON = 0.0001;
public static int sourcePoint = 1;
public static void main(String[] args) throws IOException,
InterruptedException, ClassNotFoundException, URISyntaxException {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: PageRank <EdgesPath> <verticesNum>");
System.exit(2);
}
int code = 0;
Path EdgesPath = new Path(otherArgs[0]);
int verticesNum = Integer.parseInt(otherArgs[1]);
conf.set("verticesNum", verticesNum + "");
Path cachePath = new Path(CACHED_PATH);
Path actualPath = new Path(ACTUAL_PATH);
// Delete output if exists
FileSystem hdfs = FileSystem.get(conf);
if (hdfs.exists(actualPath))
hdfs.delete(actualPath, true); // recursive delete
// prepare original distance
for (int i = 1; i <= verticesNum; i++) {
if (i == sourcePoint)
writeFileByline(ACTUAL_PATH + "/part-r-00000", i + " " + 0.0);
else
writeFileByline(ACTUAL_PATH + "/part-r-00000", i + " " + Double.POSITIVE_INFINITY);
}
int counter = 0;
boolean changed = true;
while (counter < maxIterations && changed) {
// Delete output if exists
if (hdfs.exists(cachePath))
hdfs.delete(cachePath, true);
//moving the previous iteration file to the cache directory
hdfs.rename(actualPath, cachePath);
conf.set("mapreduce.output.textoutputformat.separator", " ");
Job PageRank = Job.getInstance(conf, "SingleSourceShortestPaths " + (counter + ""));
PageRank.setJarByClass(SingleSourceShortestPaths.class);
FileInputFormat.addInputPath(PageRank, EdgesPath);
FileOutputFormat.setOutputPath(PageRank, actualPath);
PageRank.setMapperClass(SingleSourceShortestPathsMapper.class);
PageRank.setMapOutputKeyClass(IntWritable.class);
PageRank.setMapOutputValueClass(DoubleWritable.class);
PageRank.setReducerClass(SingleSourceShortestPathsReducer.class);
PageRank.setOutputKeyClass(IntWritable.class);
PageRank.setOutputValueClass(DoubleWritable.class);
// Execute job
code = PageRank.waitForCompletion(true) ? 0 : 1;
//checking if the mean is stable
BufferedReader file1Reader = new BufferedReader(new InputStreamReader(hdfs.open(new Path(CACHED_PATH + "/part-r-00000"))));
BufferedReader file2Reader = new BufferedReader(new InputStreamReader(hdfs.open(new Path(ACTUAL_PATH + "/part-r-00000"))));
for (int i = 0; i < verticesNum; i++) {
double distance1 = Double.parseDouble(file1Reader.readLine().split(" ")[1]);
double distance2 = Double.parseDouble(file2Reader.readLine().split(" ")[1]);
if (abs(distance1 - distance2) < EPSILON) {
changed = false;
} else {
changed = true;
break;
}
}
file1Reader.close();
file2Reader.close();
counter++;
System.out.println("SingleSourceShortestPaths finished iteration:>> " + counter + " || distance change: " + changed);
}
System.exit(code);
}
public static void writeFileByline(String dst, String contents) throws IOException {
Configuration conf = new Configuration();
Path dstPath = new Path(dst);
FileSystem fs = dstPath.getFileSystem(conf);
FSDataOutputStream outputStream = null;
if (!fs.exists(dstPath)) {
outputStream = fs.create(dstPath);
} else {
outputStream = fs.append(dstPath);
}
contents = contents + "\n";
outputStream.write(contents.getBytes("utf-8"));
outputStream.close();
}
}
SingleSourceShortestPathsMapper
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.*;
public class SingleSourceShortestPathsMapper extends Mapper<Object, Text, IntWritable, DoubleWritable> {
Map<Integer, Double> PointDistance = new HashMap<>();
/**
* reading the rank from the distributed cache
*/
public void setup(Context context) throws IOException, InterruptedException {
String lineString = null;
// read rank file
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
FSDataInputStream hdfsInStream = fs.open(new Path("output/cache/part-r-00000"));
InputStreamReader isr = new InputStreamReader(hdfsInStream, "utf-8");
BufferedReader br = new BufferedReader(isr);
while ((lineString = br.readLine()) != null) {
String[] keyValue = StringUtils.split(lineString, " ");
PointDistance.put(Integer.parseInt(keyValue[0]), Double.parseDouble(keyValue[1]));
}
br.close();
}
public void map(Object object, Text line, Context context) throws IOException, InterruptedException {
String[] lineData = line.toString().split(" ");
int fromPoint = Integer.parseInt(lineData[0]);
int toPoint = Integer.parseInt(lineData[1]);
double distance = Double.parseDouble(lineData[2]);
if (distance < Double.POSITIVE_INFINITY) {
context.write(new IntWritable(toPoint), new DoubleWritable(PointDistance.get(fromPoint) + distance));
context.write(new IntWritable(fromPoint), new DoubleWritable(PointDistance.get(fromPoint)));
} else
context.write(new IntWritable(toPoint), new DoubleWritable(Double.POSITIVE_INFINITY));
}
}
SingleSourceShortestPathsReducer
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class SingleSourceShortestPathsReducer extends Reducer<IntWritable, DoubleWritable, IntWritable, DoubleWritable> {
public void reduce(IntWritable key, Iterable<DoubleWritable> values, Context context) throws IOException,
InterruptedException {
double dis = Double.POSITIVE_INFINITY;
for (DoubleWritable value : values) {
if (value.get() < dis)
dis = value.get();
}
context.write(key, new DoubleWritable(dis));
}
}
思想:
- 主要想法和之前一样,不再赘述
- 需要注意的是,每次map需要把前一次的结果也发给reduce进行比较,不然reduce出来的点个数会变少(例如原点就不会有)
运行
hadoop jar SingleSourceShortestPaths.jar input/SingleSourceShortestPaths/edges.txt 5
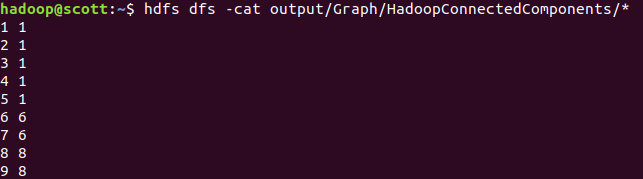
一共迭代了4次:

查看结果
hdfs dfs -cat output/Graph/HadoopSingleSourceShortestPaths/*