首先,Hive是使用了MapReduce引擎和HDFS存储的中间键,其元数据存储在MySQL,Hive只是方便查询,其数据库中的数据都在HDFS中。
安装Hadoop和Hive
在之前的分布式系统中,已经安装好Hadoop,具体教程可参考这里。
需要注意的是,在Ubuntu下,如果把环境变量放到~/.bash_profile,并不是一个好的选择,因为每次新的terminal并不会取source,因此一般放到~/.profile即可。参考这里。
测试Hadoop
创建HDFS
hdfs dfs -mkdir /user hdfs dfs -mkdir /user/test拷贝input文件到HDFS目录下
hdfs dfs -put etc/hadoop /user/test/input查看 hadoop fs -ls /user/test/input
执行mapreduce实例
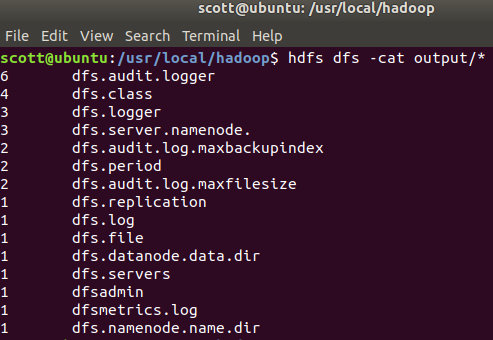
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar grep /user/test/input output 'dfs[a-z.]+'查看结果 hdfs dfs -cat output/
修改配置
首先停止服务:sbin/stop-dfs.sh
修改mapreduce配置文件:cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml vi etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
sbin/start-all.sh
这样就使用Yarn框架搭建Hadoop
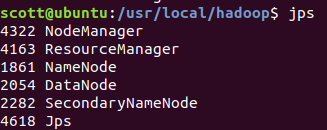
访问ResourceManger的web页面:http://localhost:8088/
MySQL安装
sudo apt-get install mysql-server 会自动安装client等其他组件
sudo mysql_secure_installation 会自动执行初始化,包括设定密码等(注意,这里的密码是当前用户的密码,而不是root密码)
重置root密码:
首先需要找到debian的默认密码:
sudo cat /etc/mysql/debian.cnf使用这个密码登录:
mysql -u debian-sys-maint -p然后依次执行
USE mysql SELECT User, Host, plugin FROM mysql.user; UPDATE user SET plugin='mysql_native_password' WHERE User='root'; COMMIT; UPDATE mysql.user SET authentication_string=PASSWORD('new_password') where user='root'; COMMIT; FLUSH PRIVILEGES; COMMIT; EXIT然后重启
sudo service mysql restart使用新密码登录:
mysql -u root -p
启动mysql:service mysql start
Hive安装
cd /usr/local/hive/conf
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
vim hive-env.sh
export HADOOP_HOME=/usr/local/hadoop
export JAVA_HOME=/usr/local/java1.8
export HIVE_HOME=/usr/local/hive
在hdfs中创建目录,并授权,用于存储文件
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir -p /user/hive/tmp
hdfs dfs -mkdir -p /user/hive/log
hdfs dfs -chmod -R 777 /user
添加mysql jdbc包
- https://dev.mysql.com/downloads/connector/j/ 选择5.1.47版本
- 解压后将文件夹里的jar包复制到 hive/lib下
新建hive/conf/hive-site.xml 文件
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123</value>
</property>
<!-- 显示表的列名 -->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!-- 显示数据库名称 -->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.support.concurrency</name>
<value>true</value>
<!-- 支持事务 -->
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
</property>
</configuration>
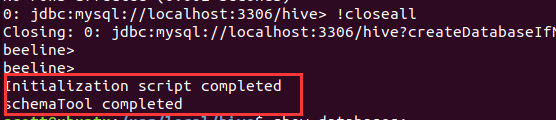
初始化hive:
schematool-dbType mysql -initSchema
如果包冲突,删除/hive/lib下的划线jar包,删除hive数据库,重新执行
执行成功:
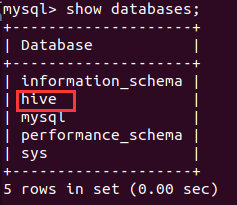
在MySQL中查看:
直接输入Hive启动hive:
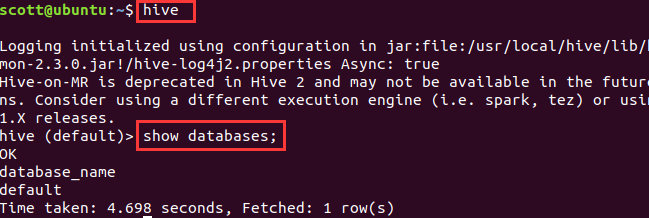
Hive
介绍
- Hive 由Facebook 实现并开源
- 是基于Hadoop 的一个数据仓库工具
- 可以将结构化的数据映射为一张数据库表
- 并提供HQL(Hive SQL)查询功能
- 底层数据是存储在HDFS 上
- Hive的本质是将SQL 语句转换为MapReduce 任务运行
- 使不熟悉MapReduce 的用户很方便地利用HQL 处理和计算HDFS 上的结构化的数据,适用于离线的批量数据计算。
测试
建立测试表
create table t1(id int,name string)
clustered by (id) into 8 buckets
stored as orc tblproperties('transactional'='true');
说明:建表语句必须带有into buckets子句和stored as orc TBLPROPERTIES (‘transactional’=’true’)子句,并且不能带有sorted by子句。
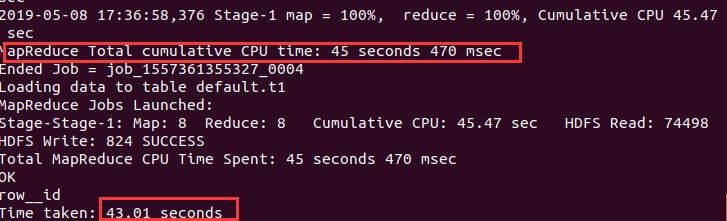
测试insert、update、delete
insert into t1 values (1,'aaa');
insert into t1 values (2,'bbb');
update t1 set name='ccc' where id=1;
delete from t1 where id=2;
可以发现Hive是通过MapReduce框架进行执行:
文件格式
文件格式选择
- 如果数据有参数化的分隔符,那么可以选择textfile格式。
- 如果数据所在文件比块尺寸(hadoop默认128MB)小,可以选择sequencefile格式
- 如果执行数据分析,并高效存储数据,可以选择RCFILE格式。
- 如果希望减小数据所需存储空间并提升性能,可以选择ORCFILE格式。
TEXTFILE普通文本文件
Hive的默认文件格式,可以向表中装载以逗号、空格、TAB作为分隔符的数据,也可以导入json格式的数据。
文本文件除了支持普通字符串、数字、日期等简单数据类型外,还支持Struct、map、array三种集合类型。
- ARRAY类型是由一系列相同数据类型的元素组成,这些元素可以通过下标来访问。比如有一个ARRAY类型的变量fruits,它是由[‘apple’,‘orange’,‘mango’]组成,那么我们可以通过fruits[1]来访问元素orange,因为ARRAY类型的下标是从0开始的。
- MAP包含key->value键值对,可以通过key来访问元素。比如”userlist”是一个map类型,其中username是key,password是value;那么我们可以通过userlist['username']来得到这个用户对应的password;
- STRUCT可以包含不同数据类型的元素。类似于一个对象,这些元素可以通过”点语法”的方式来得到所需要的元素,比如user是一个STRUCT类型,那么可以通过user.address得到这个用户的地址。
以Tab为分隔符
创建文件data.csv,内容为:
a1 1 b1 c1
a2 2 b2 c2
在Hive中导入:
create database test;
use test;
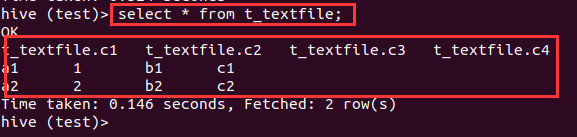
create table t_textfile(c1 string,c2 int,c3 string,c4 string)
row format delimited fields terminated by '\t' stored as textfile;
load data local inpath '/home/scott/Documents/data.csv' into table t_textfile;
select * from t_textfile;
Json格式文件
创建simple.json,内容如下:
{"foo":"abd","ba":"12341234213","a":{"aa":123,"bb":"dfg"}}
在Hive中执行命令(需要添加Jar包路径)
add jar /usr/local/hive/lib/hive-hcatalog-core-2.3.0.jar;
create table my_table(
foo string,
ba string,
a struct<aa:int,bb:string>)
row format serde 'org.apache.hive.hcatalog.data.JsonSerDe' stored as textfile;
load data local inpath '/home/scott/Documents/simple.json' into table my_table;
select foo,ba,a.aa,a.bb from my_table;

Array使用
创建文件array.txt,内容如下:
12,23,23,34 what,are,this
34,34,12,45,456 who,am,i,are
在Hive中执行命令:
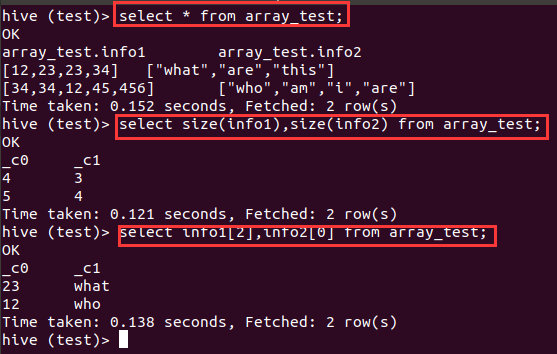
create table array_test(info1 array<int>,info2 array<string>)
row format delimited fields terminated by '\t' collection items terminated by ',' stored as textfile;
load data local inpath '/home/scott/Documents/array.txt' overwrite into table array_test;
select * from array_test;
select size(info1),size(info2) from array_test;
select info1[2],info2[0] from array_test;
Map使用
json的结构是固定的,实际应用中结构可能动态变化,用map存储动态键值对
创建文件a.json,内容如下:
{"conflict":{"liveid":123, "zhuboid":456, "media":789, "proxy":"abc", "result":1000}}
{"conflict":{"liveid":123, "zhuboid":456, "media":789, "proxy":"abc"}}
{"conflict":{"liveid":123, "zhuboid":456, "media":789}}
{"conflict":{"liveid":123}}
在Hive中执行命令:
create table json_tab(
conflict map<string,string>)
row format serde 'org.apache.hive.hcatalog.data.JsonSerDe' stored as textfile;
load data local inpath '/home/scott/Documents/a.json' overwrite into table json_tab;
select * from json_tab;
select conflict["media"] from json_tab;
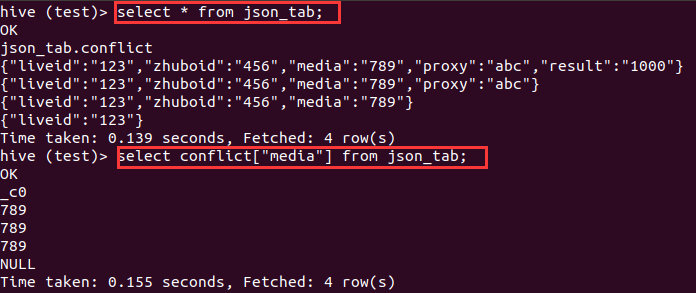
Sequence file
存储小文件,由二进制键值对组成,可分割的二进制格式,主要用途是联合多个小文件(小于块大小,默认128MB)
创建一个sequencefile类型的表:
create table t_seq(c1 string,c2 int,c3 string,c4 string)
与textfile不同,sequencefile是二进制格式,需要从其他表导入。导入后观察执行状况并查询结果。(实际执行的是一个MapReduce任务)
insert overwrite table t_seq select * from t_textfile;
select * from t_seq;
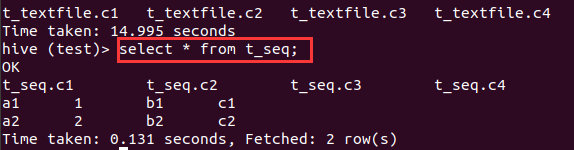
RCFILE
是高压缩率的二进制文件,采用列存储
创建一个RCFILE类型的表:
create table t_rcfile(c1 string,c2 int,c3 string,c4 string)
导入数据:
insert overwrite table t_rcfile select * from t_textfile;
select * from t_rcfile;
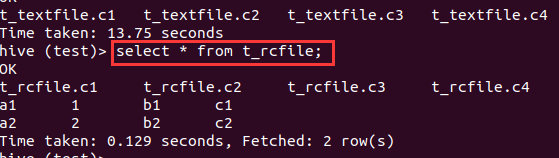
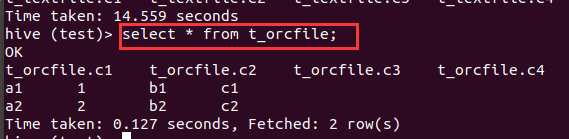
ORCFILE
(Optimized Record Columnar),相对其他格式,更优化的存储数据,提升数据处理速度,唯一支持事务的文件格式。
创建一个ORCFILE类型的表:
create table t_orcfile(c1 string,c2 int,c3 string,c4 string)
导入数据
insert overwrite table t_orcfile select * from t_textfile;
select * from t_orcfile;
Hive表分类
Hive 中的表分为内部表、外部表、分区表和Bucket 表
- 内部表和外部表的区别:
- 删除内部表,删除表元数据和数据(就是数据库中常见的表)
- 删除外部表,删除元数据,不删除数据(源数据是不存储在Hive中)
- 内部表和外部表的使用选择:
- 如果数据的所有处理都在Hive 中进行,那么倾向于选择内部表,但是如果 Hive 和其他工具要针对相同的数据集进行处理,外部表更合适。
- 使用外部表访问存储在HDFS 上的初始数据,然后通过Hive 转换数据并存到内部表中
- 分区表和 Bucket分区表区别:
- Hive 数据表可以根据某些字段进行分区操作,细化数据管理,可以让部分查询更快。同时表和分区也可以进一步被划分为Buckets,分桶表的原理和MapReduce 编程中的HashPartitioner 的原理类似。
- 分区和分桶都是细化数据管理,但是分区表是手动添加区分,由于Hive 是读模式,所以对添加进分区的数据不做模式校验,分桶表中的数据是按照某些分桶字段进行 hash散列形成的多个文件,好处是可以获得更高的查询处理效率。
外部表
创建外部表(注意,这里指定的是hdfs中的路径)
create external table fz_external_table(id int,name string,age int, tel string)
row format delimited fields terminated by ',' stored as textfile
location '/user/hive/test/external/fz_external_table';
创建文件fz_external.txt:
1,fz,25,13188888888
2,test,20,132222222
3,dx,24,18934356563
4,test1,22,11111111
查询结果:
load data local inpath '/home/scott/Documents/fz_external.txt' into table fz_external_table;
select * from fz_external_table;
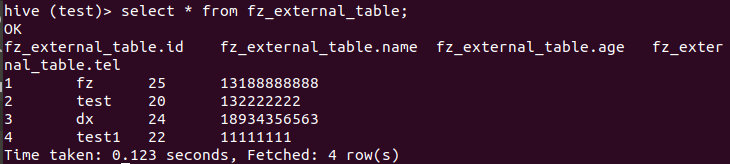
查看表,在hdfs中存在
hadoop dfs -ls /user/hive/test/external/fz_external_table
在hive中删除该表,用以上命令查看,观察结果。
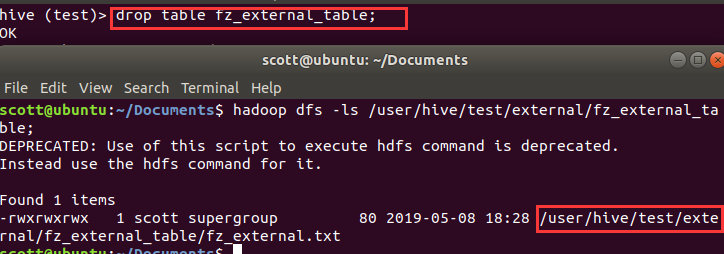
可以发现外部数据并没有删除
分区表
创建分区表
create table page_view(viewtime int,userid bigint,
page_url string,referrer_url string,
ip string comment 'ip address of the user')
comment 'this is the page view table'
partitioned by (dt string,country string)
row format delimited fields terminated by '\001' stored as sequencefile;
describe formatted page_view; 显示分区键。
创建外部分区表
创建文件a.txt:
1,a,us,ca
2,b,us,cb
3,c,ca,bb
4,d,ca,bc
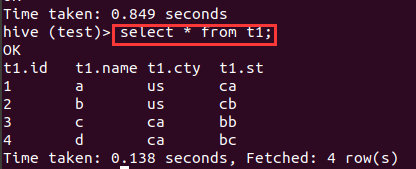
创建非分区表t1,并导入数据,查看结果
drop table if exists t1;
create table t1(id int,name string,cty string,st string)
row format delimited fields terminated by ',';
load data local inpath '/home/scott/Documents/a.txt' into table t1;
select * from t1;
create external table t2(id int, name string)
partitioned by (country string, state string)
clustered by (id) into 8 buckets
stored as orcfile;
insert into t2 partition(country, state) select * from t1;
select * from t2;
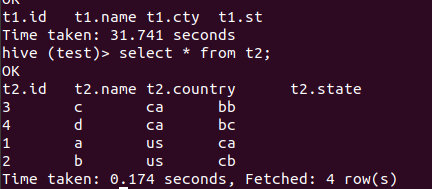
所谓分区,只是在HDFS中创建了不同key 的文件夹,可以在HDFS中查看:

总结
- clusterby key是根据key对数据进行分布,并且在每个bucket里面根据key进行排序。
- distributeby key仅仅是根据key对数据进行分布,如果同时添加sort by子句,则会保证每个bucket数据是根据sort by的key有序。
- 如果distribute by和sort by的key是相同情况下,则等价于cluster by子句。即
cluster by kes<==>distribute by keys sort by keys。 - orderby则是对整个数据进行排序,没有任何分布概念。