Hive优化
- Hive的执行依赖于底层的MapReduce作业,因此对Hadoop作业的优化或者对MapReduce作业的调整是提高Hive性能的基础。
- 大多数情况下,用户不需要了解Hive内部是如何工作的。但是当对Hive具有越来越多的经验后,学习一些Hive的底层实现细节和优化知识,会让用户更加高效地使用Hive。如果没有适当的调整,那么即使查询Hive中的一个小表,有时也会耗时数分钟才得到结果。也正是因为这个原因,Hive对于OLAP类型的应用有很大的局限性,它不适合需要立即返回查询结果的场景。然而,通过实施下面一系列的调优方法,Hive查询的性能会有大幅提高。
启用压缩
压缩可以使磁盘上存储的数据量变小,例如,文本文件格式能够压缩40%甚至更高比例,这样可以通过降低I/O来提高查询速度。
- 一个复杂的Hive查询在提交后,通常被转换为一系列中间阶段的MapReduce作业,Hive引擎将这些作业串联起来完成整个查询。可以将这些中间数据进行压缩。
在
hive/conf/hive-site.xml中添加:<!-- Hive 压缩设置 --> <property> <name>hive.exec.compress.intermediate</name> <value>true</value> </property> <property> <name>hive.intermediate.compression.codec</name> <value>org.apache.hadoop.io.compress.SnappyCodec</value> <description/> </property> <property> <name>hive.intermediate.compression.type</name> <value>BLOCK</value> </property>
当Hive将输出写入到表中时,输出内容同样可以进行压缩。我们可以设置
hive.exec.compress.output属性启用最终输出压缩。<!-- Hive 输出压缩 --> <property> <name>hive.exec.compress.output</name> <value>true</value> <description> This controls whether the final outputs of a query (to a local/hdfs file or a Hive table) is compressed. The compression codec and other options are determined from hadoop config variables mapred.output.compress* </description> </property>
优化连接
可以通过配置Map连接和倾斜连接的相关属性提升连接查询的性能。
自动Map连接
当连接一个大表和一个小表时,自动Map连接是一个非常有用的特性。如果启用了该特性,小表将保存在每个节点的本地缓存中,并在Map阶段与大表进行连接。开启自动Map连接提供了两个好处。首先,将小表装进缓存将节省每个数据节点上的读取时间。其次,它避免了Hive查询中的倾斜连接,因为每个数据块的连接操作已经在Map阶段完成了。设置下面的属性启用自动Map连接属性。
<!-- 自动map连接 --> <property> <name>hive.auto.convert.join</name> <value>true</value> </property> <property> <name>hive.auto.convert.join.noconditionaltask</name> <value>true</value> </property> <property> <name>hive.auto.convert.join.noconditionaltask.size</name> <value>10000000</value> </property> <property> <name>hive.auto.convert.join.use.nonstaged</name> <value>true</value> </property>hive.auto.convert.join:是否启用基于输入文件的大小,将普通连接转化为Map连接的优化机制。hive.auto.convert.join.noconditionaltask:假设参与连接的表(或分区)有N个,如果打开这个参数,并且有N-1个表(或分区)的大小总和小于hive.auto.convert.join.noconditionaltask.size参数指定的值,那么会直接将连接转为Map连接。hive.auto.convert.join.use.nonstaged:对于条件连接,如果从一个小的输入流可以直接应用于join操作而不需要过滤或者投影,那么不需要通过MapReduce的本地任务在分布式缓存中预存。
倾斜Map连接(某个连接键对应的行数过多的情况)
<property> <name>hive.optimize.skewjoin</name> <value>true</value> </property> <property> <name>hive.skewjoin.key</name> <value>100000</value> </property> <property> <name>hive.skewjoin.mapjoin.map.tasks</name> <value>10000</value> </property> <property> <name>hive.skewjoin.mapjoin.min.split</name> <value>3354432</value> </property>hive.optimize.skewjoin:是否为连接表中的倾斜键创建单独的执行计划。hive.skewjoin.key:决定如何确定连接中的倾斜键。hive.skewjoin.mapjoin.map.tasks:指定倾斜连接中,用于Map连接作业的任务数。hive.skewjoin.mapjoin.min.split:通过指定最小split的大小,确定Map连接作业的任务数。
桶Map连接(连接中使用的表是按特定列分桶)
<property> <name>hive.optimize.bucketmapjoin</name> <value>true</value> </property> <property> <name>hive.optimize.bucketmapjoin.sortedmerge</name> <value>true</value> </property>hive.optimize.bucketmapjoin:是否尝试桶Map连接。hive.optimize.bucketmapjoin.sortedmerge:是否尝试在Map连接中使用归并排序。
避免全局排序
Hive中使用order by子句实现全局排序。orderby只用一个Reducer产生结果,对于大数据集,这种做法效率很低。如果不需要全局有序,则可以使用sortby子句,该子句为每个reducer生成一个排好序的文件。如果需要控制一个特定数据行流向哪个reducer,可以使用distribute by子句。例如:
Selectid,name, salary, dept fromemployee distribute by dept sort by id asc, name desc;属于一个dept的数据会分配到同一个reducer进行处理,同一个dept的所有记录按照id、name列排序。最终的结果集是全局有序的。
优化limit操作
默认时limit操作仍然会执行整个查询,然后返回限定的行数。在有些情况下这种处理方式很浪费,因此可以通过设置下面的属性避免此行为。
<property> <name>hive.limit.optimize.enable</name> <value>true</value> </property> <property> <name>hive.limit.row.max.size</name> <value>100000</value> </property> <property> <name>hive.limit.optimize.limit.file</name> <value>10</value> </property> <property> <name>hive.limit.optimize.fetch.max</name> <value>50000</value> </property>
hive.limit.optimize.enable:是否启用limit优化。当使用limit语句时,对源数据进行抽样。hive.limit.row.max.size:在使用limit做数据的子集查询时保证的最小行数据量。hive.limit.optimize.limit.file:在使用limit做数据子集查询时,采样的最大文件数。hive.limit.optimize.fetch.max:使用简单limit数据抽样时,允许的最大行数。
启用并行执行
每条HiveQL语句都被转化成一个或多个执行阶段,可能是一个MapReduce阶段、采样阶段、归并阶段、限制阶段等。默认时,Hive在任意时刻只能执行其中一个阶段。如果组成一个特定作业的多个执行阶段是彼此独立的,那么它们可以并行执行,从而整个作业得以更快完成。通过设置下面的属性启用并行执行。
<property> <name>hive.exec.parallel</name> <value>true</value> </property> <property> <name>hive.exec.parallel.thread.number</name> <value>8</value> </property>hive.exec.parallel:是否并行执行作业。hive.exec.parallel.thread.number:最多可以并行执行的作业数。
使用单一Reduce
通过为group by操作开启单一reduce任务属性,可以将一个查询中的多个group by操作联合在一起发送给单一MapReduce作业。
<property>
<name>hive.multigroupby.singlereducer</name>
<value>true</value>
</property>
控制并行Reduce任务
Hive通过将查询划分成一个或多个MapReduce任务达到并行的目的。确定最佳的mapper个数和reducer个数取决于多个变量,例如输入的数据量以及对这些数据执行的操作类型等。如果有太多的mapper或reducer任务,会导致启动、调度和运行作业过程中产生过多的开销,而如果设置的数量太少,那么就可能没有充分利用好集群内在的并行性。对于一个Hive查询,可以设置下面的属性来控制并行reduce任务的个数。
<property> <name>hive.exec.reducers.bytes.per.reducer</name> <value>256000000</value> </property> <property> <name>hive.exec.reducers.max</name> <value>1009</value> </property>hive.exec.reducers.bytes.per.reducer:每个reducer的字节数,默认值为256MB。Hive是按照输入的数据量大小来确定reducer个数的。例如,如果输入的数据是1GB,将使用4个reducer。hive.exec.reducers.max:将会使用的最大reducer个数。
启用向量化
通过查询执行向量化,使Hive从单行处理数据改为批量处理方式,具体来说是一次处理1024行而不是原来的每次只处理一行,这大大提升了指令流水线和缓存的利用率,从而提高了表扫描、聚合、过滤和连接等操作的性能。
<property> <name>hive.vectorized.execution.enabled</name> <value>true</value> </property> <property> <name>hive.vectorized.execution.reduce.enabled</name> <value>true</value> </property> <property> <name>hive.vectorized.execution.reduce.groupby.enabled</name> <value>true</value> </property>hive.vectorized.execution.enabled:如果该标志设置为true,则开启查询执行的向量模式,默认值为false。hive.vectorized.execution.reduce.enabled:如果该标志设置为true,则开启查询执行reduce端的向量模式,默认值为truehive.vectorized.execution.reduce.groupby.enabled:如果该标志设置为true,则开启查询执行reduce端group by操作的向量模式,默认值为true。
启用基于成本的优化器
Hive的CBO也可以根据查询成本制定执行计划,例如确定表连接的顺序、以何种方式执行连接、使用的并行度等。设置下面的属性启用基于成本优化器。
<property> <name>hive.cbo.enable</name> <value>true</value> </property> <property> <name>hive.compute.query.using.stats</name> <value>true</value> </property> <property> <name>hive.stats.fetch.partition.stats</name> <value>true</value> </property> <property> <name>hive.stats.fetch.column.stats</name> <value>true</value> </property>hive.cbo.enable:控制是否启用基于成本的优化器,默认值是true。hive.compute.query.using.stats:该属性的默认值为false。如果设置为true,Hive在执行某些查询时,例如selectcount(1),只利用元数据存储中保存的状态信息返回结果。为了收集基本状态信息,需要将hive.stats.autogather属性配置为true。为了收集更多的状态信息,需要运行analyzetable查询命令。hive.stats.fetch.partition.stats:该属性的默认值为true。操作树中所标识的统计信息,需要分区级别的基本统计,如每个分区的行数、数据量大小和文件大小等。分区统计信息从元数据存储中获取。如果存在很多分区,要为每个分区收集统计信息可能会消耗大量的资源。这个标志可被用于禁止从元数据存储中获取分区统计。当该标志设置为false时,Hive从文件系统获取文件大小,并根据表结构估算行数。hive.stats.fetch.column.stats:该属性的默认值为false。操作树中所标识的统计信息,需要列统计。列统计信息从元数据存储中获取。如果存在很多列,要为每个列收集统计信息可能会消耗大量的资源。这个标志可被用于禁止从元数据存储中获取列统计。
Crontab
- cron是linux下用来周期性的执行某种任务或等待处理某些事件的一个守护进程,与windows下的计划任务类似,当安装完成操作系统后,默认会安装此服务工具,并且会自动启动crond进程,crond进程每分钟会定期检查是否有要执行的任务,如果有要执行的任务,则自动执行该任务。
- Linux下的任务调度分为两类,系统任务调度和用户任务调度。
- 系统任务调度:系统需要周期性执行的工作,比如写缓存数据到硬盘、日志清理等。在
/etc目录下有一个crontab文件,这个就是系统任务调度的配置文件。 - 用户任务调度:用户要定期执行的工作,比如用户数据备份、定时邮件提醒等。用户可以使用crontab命令来定制自己的计划任务。所有用户定义的crontab文件都被保存在
/var/spool/cron目录中,其文件名与用户名一致。
- 系统任务调度:系统需要周期性执行的工作,比如写缓存数据到硬盘、日志清理等。在
Crontab权限
- Linux系统使用一对allow/deny文件组合判断用户是否具有执行crontab的权限。
- 如果用户名出现在
/etc/cron.allow文件中,则该用户允许执行crontab命令。如果此文件不存在,那么如果用户名没有出现在/etc/cron.deny文件中,则该用户允许执行crontab命令。 - 如果只存在cron.deny文件,并且该文件是空的,则所有用户都可以使用crontab命令。
- 如果这两个文件都不存在,那么只有root用户可以执行crontab命令。allow/deny文件由每行一个用户名构成。
Crontab命令
crontab [-u user] file
crontab [-u user] [-e | -l -r]
-u user:用来设定某个用户的crontab服务,此参数一般由root用户使用。file:file是命令文件的名字,表示将file作为crontab的任务列表文件并载入crontab。如果在命令行中没有指定这个文件,crontab命令将接受标准输入,通常是键盘上键入的命令,并将它们载入crontab。-e:编辑某个用户的crontab文件内容。如果不指定用户,则表示编辑当前用户的crontab文件。如果文件不存在,则创建一个。-l:显示某个用户的crontab文件内容,如果不指定用户,则表示显示当前用户的crontab文件内容。-r:从/var/spool/cron目录中删除某个用户的crontab文件,如果不指定用户,则默认删除当前用户的crontab文件。- 注意: 如果不经意地输入了不带任何参数的crontab命令,不要使用Control-d退出,因为这会删除用户所对应的crontab文件中的所有条目。代替的方法是用Control-c退出。
Crontab文件
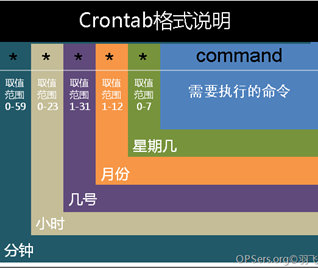
- 用户所建立的crontab文件中,每一行都代表一项任务,每行的每个字段代表一项设置。它的格式共分为六个字段,前五段是时间设定段,第六段是要执行的命令段,格式如下:
- 星号(*):代表所有可能的值。
- 逗号(,):指定一个列表范围,例“1,2,5,7,8,9”。
- 中杠(-):表示一个整数范围,例如“2-6”表示“2,3,4,5,6”。
- 正斜线(/):可以用正斜线指定时间的间隔频率,例如“0-23/2”表示每两小时执行一次。
执行
- 脚本中涉及文件路径时写绝对路径;
- 脚本执行要用到环境变量时,通过source命令显式引入
- 当手动执行脚本没问题,但是crontab不执行时,可以尝试在crontab中直接引入环境变量解决问题
- 可以将crontab执行任务的输出信息重定向到一个自定义的日志文件中