日期纬度装载
- 日期维度在数据仓库中是一个特殊角色。日期维度包含时间概念,而时间是最重要的,因为数据仓库的主要功能之一就是存储历史数据,所以每个数据仓库里的数据都有一个时间特征。
- 装载日期数据有三个常用方法:
- 预装载(最常见,最容易实现)
- 每日装载一天
- 从源数据装载日期
- MySQL可以使用存储过程来插入数据,但是Hive不支持,所以使用shell脚本来执行日期的装载。
#!/bin/bash
date1="{% math_inline %}1"
date2="{% endmath_inline %}2"
tempdate=`date -d "{% math_inline %}date1" +%F`
tempdateSec=`date -d "{% endmath_inline %}date1" +%s`
enddateSec=`date -d "{% math_inline %}date2" +%s`
min=1
max=`expr \( {% endmath_inline %}enddateSec - {% math_inline %}tempdateSec \) / \( 24 \* 60 \* 60 \) + 1`
cat /dev/null > ./date_dim.csv
while [ {% endmath_inline %}min -le {% math_inline %}max ]
do
month=`date -d "{% endmath_inline %}tempdate" +%m`
month_name=`date -d "{% math_inline %}tempdate" +%B`
quarter=`echo {% endmath_inline %}month | awk '{print int(({% math_inline %}0-1)/3)+1}'`
year=`date -d "{% endmath_inline %}tempdate" +%Y`
echo {% math_inline %}{min}","{% endmath_inline %}{tempdate}","{% math_inline %}{month}","{% endmath_inline %}{month_name}","{% math_inline %}{quarter}","{% endmath_inline %}{year}
>> ./date_dim.csv
tempdate=`date -d "+{% math_inline %}min day {% endmath_inline %}date1" +%F`
tempdateSec=`date -d "+{% math_inline %}min day {% endmath_inline %}date1" +%s`
min=`expr $min + 1`
done
执行脚本,并生成日期纬度
./date_dim_generate.sh 2000-01-01 2020-12-31
hdfs dfs -put -f date_dim.csv /user/hive/warehouse/dw.db/date_dim/
数据抽取
逻辑数据映射
- 逻辑数据映射就是指源系统中的对象和目标数据仓库中的对象之间的对应关系,是建立ETL物理工作计划的指南。
- 包括三个组件:
- 目标组件。包括数据仓库中出现的物理表名称、表类型(事实表、维度表和子维度表等)、列名称、列的数据类型等。
- 源系统组件。包括数据源名称、源表名、源列名及其数据类型。
- 转换。源数据与期望的目标数据仓库格式对应所需的详细操作。
数据抽取方式
- 需要抽取哪部分源数据加载到数据仓库?有两种可选方式,完全抽取和变化数据捕获。
- 数据抽取的方向是什么?有两种方式,
- 拉模式,即数据仓库主动去源系统拉取数据;
- 推模式,由源系统将自己的数据推送给数据仓库。
- 对于方向,要改变或增加操作型业务系统的功能是非常困难,理论上讲,数据仓库不应该要求对源系统做任何改造。故选择拉模式。
- 数据量很小并且易处理,一般来说采取完全源数据抽取;如果源数据量很大,抽取全部数据不可行,只能抽取变化的源数据,这种数据抽取模式称为变化数据捕获,简称CDC。
CDC
- 基于时间戳的CDC
- 要求源数据里有相关的属性列,抽取过程可以利用这些属性列来判断哪些数据是增量数据。最常见的属性列有以下两种。
- 时间戳:这种方法至少需要一个更新时间戳,但最好有两个,一个插入时间戳,表示记录何时创建;一个更新时间戳,表示记录最后一次更新的时间。
- 序列:大多数数据库系统都提供自增功能。如果数据库表列被定义成自增的,就可以很容易地根据该列识别出新插入的数据。
- 缺点:不能区分插入和更新操作;不能记录删除记录的操作;无法识别多次更新;不具有实时能力。
- 要求源数据里有相关的属性列,抽取过程可以利用这些属性列来判断哪些数据是增量数据。最常见的属性列有以下两种。
- 基于触发器的CDC
- 当执行INSERT、UPDATE、DELETE这些SQL语句时,可以激活数据库里的触发器,并执行一些动作,就是说触发器可以用来捕获变更的数据并把数据保存到中间临时表里。然后这些变更的数据再从临时表中取出,被抽取到数据仓库的过渡区里。
- 缺点:大多数场合下,不允许向操作型数据库里添加触发器,降低系统的性能。
- 基于快照的CDC
- 通过比较源表和快照表来获得数据变化。快照就是一次性抽取源系统中的全部数据,把这些数据装载到数据仓库的过渡区中。
- 可以用全外连接比较源表与快照的差别。
- 缺点:需要大量的存储空间来保存快照。另外,当表很大时,这种查询会有比较严重的性能问题。
- 基于日志的CDC
- 实时从数据库日志中读取到所有数据库写操作,并使用这些操作来更新数据仓库中的数据。需要将日志的二进制格式转换为可以理解的格式(例如,mysqlbinlog)
- 缺点:实现复杂
实验
导出文本文件
show global variables like '%secure%';
use source;
select * into outfile '/var/lib/mysql-files/product.txt' fields terminated by ',' from product;
使用mysqldump命令行工具,可以一次性导出多个表、多个库或所有库的数据,进入目标文件夹查看是否导入成功
sudo mysqldump -uroot -p123 source product -t -T /var/lib/mysql-files/ --fields-terminated-by=,
// -t表示不导出create信息,-T参数指定导出文件的位置
Sqoop
Sqoop是一个在Hadoop与结构化数据存储(如关系数据库)之间高效传输大批量数据的工具。
Sqoop的安装可参考这里。
Sqoop 显示数据库列表(需要MySQL的Jar包放入Sqoop/lib)
sqoop list-datavases --connect jdbc:mysql://localhost:3306/ --username root --password 123
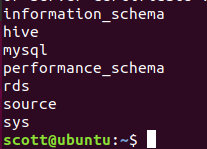
Sqoop显示数据库的表
sqoop list-tables --connect jdbc:mysql://localhost:3306/source --username root --password 123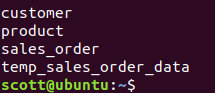
例子
把MySQL中testdb.PERSON表的数据导入HDFS。
在mysql中创建数据库test,在test中创建表test1并插入两条数据。
create database test; use test; create table test1(id int,name varchar(10)); insert into test1 values(1,'aaa'); insert into test1 values(2,'bbb'); select * from test1;
使用sqoop导出数据
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123 --table test1 --target-dir /user/test/test1 --split-by id -m 1
查看结果
hdfs dfs -ls /user/test/test1

把HDFS的表导入mysql中
清空mysql 中test1表
truncate table test1; select * from test1;
sqoop执行导入
sqoop export --connect jdbc:mysql://localhost:3306/test --username root --password 123 --table test1 --export-dir /user/test/test1
使用Sqoop抽取数据
首先将java-json.jar包加入sqoop/lib中,在这里下载
将hive/lib下的hive-common-2.3.0.jar 拷贝到sqoop/lib下。
建立sqoop增量导入作业,使用sqoop job -list 查看。
##创建作业
sqoop job --create myjob_1 \
-- \
import \
--connect "jdbc:mysql://localhost:3306/source?useSSL=false&user=root&password=scott5183" \
--table sales_order \
--columns "order_number, customer_number, product_code, order_date, entry_date, order_amount" \
--where "entry_date < current_date()" \
--hive-import \
--hive-table rds.sales_order \
--incremental append \
--check-column entry_date \
--last-value '1900-01-01'
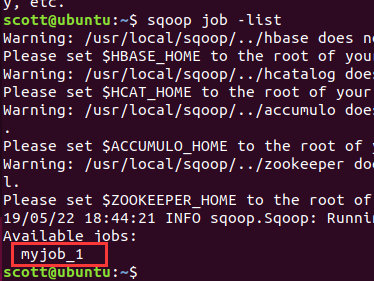
查看此时作业中保存的last-value
sqoop job --show myjob_1 | grep last.value

增量导入,执行sqoop job --exec myjob_1
查看此时作业中保存的last-value

在MySQL中执行(增加两条数据)
use source;
set @customer_number := floor(1 + rand()* 6);
set @product_code := floor(1 + rand()* 2);
set @order_date := from_unixtime(unix_timestamp('2016-07-03') + rand()*(unix_timestamp('2016-07-04') - unix_timestamp('2016-07-03')));
set @amount := floor(1000 + rand() * 9000);
insert into sales_order values(101,@customer_number,@product_code,@order_date,@order_date,@amount);
set @customer_number := floor(1 + rand()* 6);
set @product_code := floor(1 + rand()* 2);
set @order_date := from_unixtime(unix_timestamp('2016-07-04') + rand()*(unix_timestamp('2016-07-05') - unix_timestamp('2016-07-04')));
set @amount := floor(1000 + rand()* 9000);
insert into sales_order values(102,@customer_number,@product_code,@order_date,@order_date,@amount);
commit;

在hive的rds库里查询,前两行记录如下所示。
select * from sales_order where order_number in (101,102);
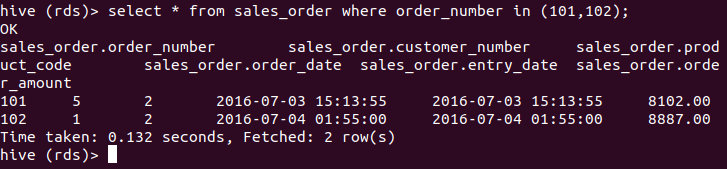
还原数据
use source;
delete from sales_order where order_number in (101,102);
alter table sales_order auto_increment=101;