Hive 装载数据
- load与load overwrite的区别是:load每次执行生成新的数据文件,文件中是本次装载的数据。load overwrite如表(或分区)的数据文件不存在则生成,存在则重新生成数据文件内容。
- 分区表比非分区表多了一种alter table ... add partition的数据装载方式。
- 对于分区表(无论内部还是外部),load与load overwrite会自动建立名为分区键值的目录,而alter table ... add partition,只要用location指定数据文件所在的目录即可。
- 对于外部表,除了在删除表时只删除元数据而保留表数据目录外,其数据装载行为与内部表相同。
load追加数据
首先生成数据并查看在warehouse中的数据
drop table if exists t1;
create table t1(name string);
load data local inpath '/home/scott/Documents/a.txt' into table t1;
select * from t1;
hdfs dfs -ls /user/hive/warehouse/test.db/t1;
hdfs dfs -cat /user/hive/warehouse/test.db/t1/a.txt;
可以发现,文件被写入到HDFS中

追加数据
echo 'bbbb' >> a.txt;
load data local inpath '/home/scott/Documents/a.txt' into table t1;
select * from t1;
hdfs dfs -ls /user/hive/warehouse/test.db/t1;
hdfs dfs -cat /user/hive/warehouse/test.db/t1/a.txt;
可以发现,在HDFS中是直接追加了一个文件。

Load overwrite
使用overwrite关键字,会将直接的数据覆盖
drop table if exists t2;
create table t2(name string);
load data local inpath '/home/scott/Documents/a.txt' into table t2;
select * from t2;
hdfs dfs -ls /user/hive/warehouse/test.db/t2;
hdfs dfs -cat /user/hive/warehouse/test.db/t2/a.txt;
追加数据
echo 'cccc' >> a.txt;
load data local inpath '/home/scott/Documents/a.txt' overwrite into table t2;
select * from t2;
hdfs dfs -ls /user/hive/warehouse/test.db/t2;
hdfs dfs -cat /user/hive/warehouse/test.db/t2/a.txt;
可以发现,overwrite之后依然只有一个文件,就是最后load 的文件。
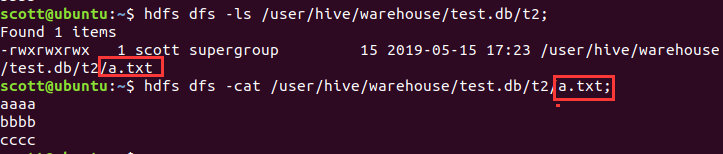
动态分区插入
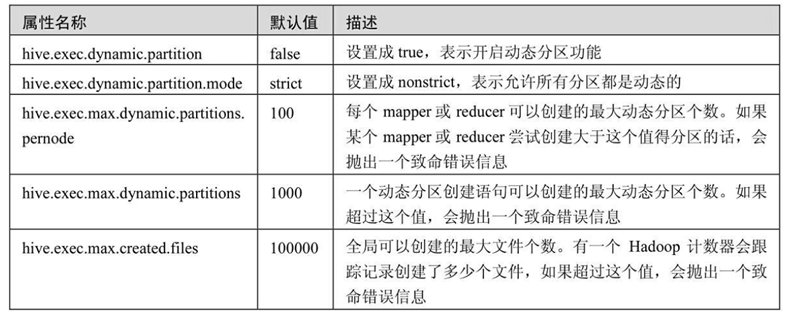
动态分区功能默认情况下是不开启的。分区以“严格”模式执行,在这种模式下要求至少有一个分区列是静态的。这有助于阻止因设计错误导致查询产生大量的分区。还有一些属性用于限制资源使用。
在本地文件a.txt中写入数据:
aaa,US,CA
aaa,US,CB
bbb,CA,BB
bbb,CA,BC
建立非分区表并装载数据
drop table if exists t1;
create table t1(name string,city string,st string) row format delimited fields terminated by ',';
load data local inpath '/home/scott/Documents/a.txt' overwrite into table t1;
select * from t1;
hdfs dfs -ls /user/hive/warehouse/test.db/t1;
此时数据未分区

建立外部分区表并动态装载数据
drop table if exists t2;
create external table t2 (name string) partitioned by (country string, state string);
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=1000;
insert into table t2 partition(country,state) select name,city,st from t1;
insert into table t2 partition(country,state) select name,city,st from t1;
select * from t2;
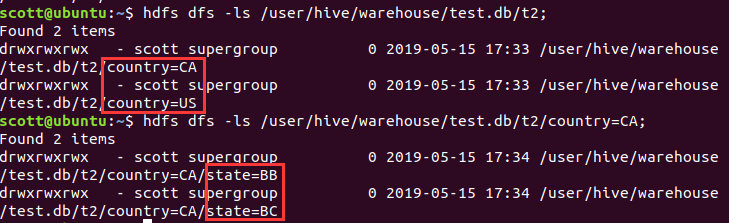
hdfs dfs -ls /user/hive/warehouse/test.db/t2;
这里实际上插入了两次相同的数据,向外部分区表中装载了8条数据,动态建立了两个分区目录。
若在Hive中删除了外部表的元数据,但在HDFS中数据还在,因此需要恢复数据及分区。Hive提供了MSCK REPAIR TABLE的方法直接根据文件夹恢复分区。
create external table t2 (name string) partitioned by (country string, state string) row format delimited fields terminated by ',' LOCATION '/user/hive/warehouse/test.db/t2' ;
MSCK REPAIR TABLE t2;
构建数据仓库模型
创建销售订单数据仓库中的表。
在这个场景中,源数据库表就是操作型系统的模拟。我们在MySQL中建立源数据库表。RDS存储原始数据,作为源数据到数据仓库的过渡,在Hive中建立RDS库表。TDS即为转化后的多维数据仓库,在Hive中建立TDS库表。
在MySQL中建立源数据库表:mysql -u root -p
-- 建立源数据库
drop database if exists source;
create database source;
use source;
-- 建立客户表
create table customer (
customer_number int not null auto_increment primary key comment '客户编号,主键',
customer_name varchar(50) comment '客户名称',
customer_street_address varchar(50) comment '客户住址',
customer_zip_code int comment '邮编',
customer_city varchar(30) comment '所在城市',
customer_state varchar(2) comment '所在省份'
);
-- 建立产品表
create table product (
product_code int not null auto_increment primary key comment '产品编码,主键',
product_name varchar(30) comment '产品名称',
product_category varchar(30) comment '产品类型'
);
-- 建立销售订单表
create table sales_order (
order_number int not null auto_increment primary key comment '订单号,主键',
customer_number int comment '客户编号',
product_code int comment '产品编码',
order_date datetime comment '订单日期',
entry_date datetime comment '登记日期',
order_amount decimal(10 , 2 ) comment '销售金额',
foreign key (customer_number)
references customer (customer_number)
on delete cascade on update cascade,
foreign key (product_code)
references product (product_code)
on delete cascade on update cascade
)
生成测试数据
use source;
##生成客户表测试数据
insert into customer (customer_name,customer_street_address,customer_zip_code,customer_city,customer_state) values ('really large customers', '7500 louise dr.',17050, 'mechanicsburg','pa'),
('small stores', '2500 woodland st.',17055, 'pittsburgh','pa'),
('medium retailers','1111 ritter rd.',17055,'pittsburgh','pa'),
('good companies','9500 scott st.',17050,'mechanicsburg','pa'),
('wonderful shops','3333 rossmoyne rd.',17050,'mechanicsburg','pa'),
('loyal clients','7070 ritter rd.',17055,'pittsburgh','pa'),
('distinguished partners','9999 scott st.',17050,'mechanicsburg','pa');
##生成产品表测试数据
insert into product (product_name,product_category)
values
('hard disk drive', 'storage'),
('floppy drive', 'storage'),
('lcd panel', 'monitor');
##生成100条销售订单表测试数据
drop procedure if exists generate_sales_order_data;
delimiter //
create procedure generate_sales_order_data()
begin
drop table if exists temp_sales_order_data;
create table temp_sales_order_data as select * from sales_order where 1=0;
set @start_date := unix_timestamp('2016-03-01');
set @end_date := unix_timestamp('2016-07-01');
set @i := 1;
while @i<=100 do
set @customer_number := floor(1 + rand()* 6);
set @product_code := floor(1 + rand()* 2);
set @order_date := from_unixtime(@start_date + rand()* (@end_date - @start_date));
set @amount := floor(1000 + rand()* 9000);
insert into temp_sales_order_data values (@i,@customer_number,@product_code,@order_date,@order_date,@amount);
set @i:=@i+1;
end while;
truncate table sales_order;
insert into sales_order select null,customer_number,product_code,order_date,entry_date,order_amount from temp_sales_order_data order by order_date;
commit;
end
//
delimiter ;
call generate_sales_order_data();
在Hive中建立RDS库表:
drop database if exists rds cascade;
create database rds;
use rds;
-- 建立客户过渡表
CREATE TABLE customer ( customer_number INT comment 'number', customer_name VARCHAR(30) comment 'name', customer_street_address VARCHAR(30) comment 'address', customer_zip_code INT comment 'zipcode', customer_city VARCHAR(30) comment 'city', customer_state VARCHAR(2) comment 'state');
-- 建立产品过渡表
CREATE TABLE product ( product_code INT comment 'code', product_name VARCHAR(30) comment 'name', product_category VARCHAR(30) comment 'category' );
-- 建立销售订单过渡表
CREATE TABLE sales_order ( order_number INT comment 'order number', customer_number INT comment 'customer number', product_code INT comment 'product code', order_date TIMESTAMP comment 'order date', entry_date TIMESTAMP comment 'entry date', order_amount DECIMAL(10 , 2 ) comment 'order amount');
在Hive中建立TDS库表
drop database if exists dw cascade;
create database dw;
use dw;
-- 建立时间维度
create table date_dim(
date_sk int,
`date` date,
month tinyint,
month_name varchar(9),
quarter tinyint,
year smallint
)
row format delimited fields terminated by ',' stored as textfile;
-- 建立客户维度表
create table customer_dim (
customer_sk int,
customer_number int,
customer_name varchar(50),
customer_street_address varchar(50),
customer_zip_code int,
customer_city varchar(30),
customer_state varchar(2),
version int,
effective_date date,
expiry_date date
)clustered by(customer_sk) into 8 buckets
stored as orc tblproperties('transactional' = 'true');
-- 建立产品维度表
create table product_dim (
product_sk int,
product_code int,
product_name varchar(30),
product_category varchar(30),
version int,
effective_date date,
expiry_date date
)clustered by(product_sk) into 8 buckets
stored as orc tblproperties('transactional' = 'true');
-- 建立订单维度表
create table order_dim (
order_sk int,
order_number int,
version int,
effective_date date,
expiry_date date
)clustered by(order_sk) into 8 buckets
stored as orc tblproperties('transactional' = 'true');
-- 建立销售订单事实表
create table sales_order_fact (
order_sk int,
customer_sk int,
product_sk int,
order_date_sk int,
order_amount decimal(10 , 2 )
)clustered by(order_sk) into 8 buckets
stored as orc tblproperties('transactional' = 'true');